Efficiency#
Learning Objectives
After reading this chapter, you will be able to:
Design experiments to measure time and space overhead for private algorithms
Consider tradeoffs between space and time efficiency
Consider techniques for optimization
Describe the efficiency bottlenecks in differentially private algorithms
Time Efficiency of Differential Privacy#
In a situation where the application of differential privacy is implemented as a direct loop over sensitive entities, there is a significant time cost incurred from the added burden of random number generation.
We can contrast the runtime performance of two versions of a counting query - one with differential privacy, and one without it.
import itertools
import operator
import time
def time_count(k):
l = [1] * k
start = time.perf_counter()
_ = list(itertools.accumulate(l, func=operator.add))
stop = time.perf_counter()
return stop - start
def time_priv_count(k):
l = [1] * k
start = time.perf_counter()
_ = list(itertools.accumulate(l, func=lambda x, y: x + laplace_mech(y,1,0.1), initial=0))
stop = time.perf_counter()
return stop - start
x_axis = [k for k in range(100_000,1_000_000,100_000)]
plt.xlabel('Size (N)')
plt.ylabel('Time (Seconds)')
plt.plot(x_axis, [time_count(k) for k in range(100_000,1_000_000,100_000)], label='Regular Count')
plt.plot(x_axis, [time_priv_count(k) for k in range(100_000,1_000_000,100_000)], label='Private Count')
plt.legend();
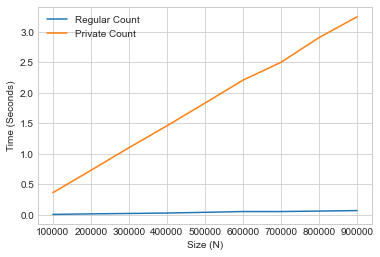
With the time spent counting on the y-axis, and the list lize on the x-axis, we can see that the time complexity of differential privacy for this particular operation is essentially linear in the size of the input.
The good news is that the above implementation of differentially private count is rather naive, and we can do much better using optimization techniques such as vectorization!
For example, when implementing differential privacy for the machine learning operations in a previous chapter, we make use of NumPy functions which are heavily optimized for vector-based operations. In this particular scenario, leveraging this strategy, we manage to incur negligible time cost for the use of differential privacy.
delta = 1e-5
def time_gd(k):
start = time.perf_counter()
gradient_descent(k)
stop = time.perf_counter()
return stop - start
def time_priv_gd(k):
start = time.perf_counter()
noisy_gradient_descent(k, 0.1, delta)
stop = time.perf_counter()
return stop - start
x_axis = [k for k in range(10,100,25)]
plt.xlabel('Size (N)')
plt.ylabel('Time (Seconds)')
plt.plot(x_axis, [time_gd(k) for k in range(10,100,25)], label='Regular GD')
plt.plot(x_axis, [time_priv_gd(k) for k in range(10,100,25)], label='Private GD')
plt.legend();
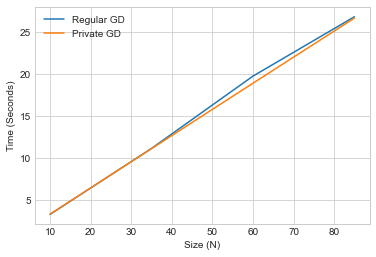
The graph plots generally overlap or are close in most simulations of this experiment, indicating low (constant) time inefficiency overhead incurred from utilizing private gradient descent.
Space Cost of Differential Privacy#
We can also analyze the space utilization of differential privacy mechanisms. Python3 (3.4) introduces a debug tool capable of tracing memory blocks allocated for use during evaluation. We may perform our analysis of space overhead by comparing the peak size of memory blocks used during private versus non-private computation.
Using this strategy, we can analyze the space overhead of the private count operation as follows:
import itertools
import operator
import tracemalloc
def space_count(k):
l = [1] * k
itertools.accumulate(l, func=operator.add)
_, peak = tracemalloc.get_traced_memory()
tracemalloc.reset_peak()
return peak/1000
def space_priv_count(k):
l = [1] * k
itertools.accumulate(l, func=lambda x, y: x + laplace_mech(y,1,0.1), initial=0)
_, peak = tracemalloc.get_traced_memory()
tracemalloc.reset_peak()
return peak/1000
tracemalloc.start()
x_axis = [k for k in range(100_000,1_000_000,100_000)]
plt.xlabel('Size (N)')
plt.ylabel('Memory Blocks')
plt.plot(x_axis, [space_count(k) for k in range(100_000,1_000_000,100_000)], label='Regular Count')
plt.plot(x_axis, [space_priv_count(k) for k in range(100_000,1_000_000,100_000)], label='Private Count')
tracemalloc.stop()
plt.legend();
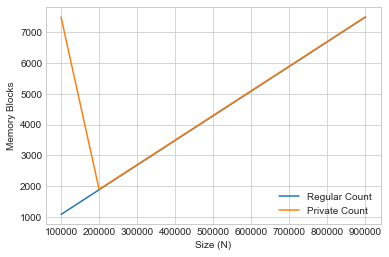
We display every thousand memory blocks on the y-axis, against the list size on the x-axis.
In this case, the memory complexity of differential privacy is generally constant.
We also observe a spike in the initial space cost for private count, which we can attribute to memory allocation for setup of the random number generator resources such as the entropy pool and PRNG (pseudo-random number generator).
We can repeat this experiment to contrast private and non-private machine learning:
def space_gd(k):
gradient_descent(k)
_, peak = tracemalloc.get_traced_memory()
tracemalloc.reset_peak()
return peak/1_000_000
def space_priv_gd(k):
noisy_gradient_descent(k, 0.1, delta)
_, peak = tracemalloc.get_traced_memory()
tracemalloc.reset_peak()
return peak/1_000_000
tracemalloc.start()
x_axis = [k for k in range(5,10,2)]
plt.xlabel('Size (N)')
plt.ylabel('Memory Blocks')
plt.plot(x_axis, [space_gd(k) for k in range(5,10,2)], label='Regular GD')
plt.plot(x_axis, [space_priv_gd(k) for k in range(5,10,2)], label='Private GD')
tracemalloc.stop()
plt.legend();
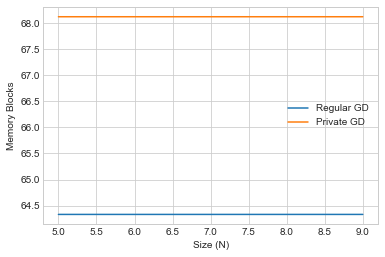
In this case, since we are performing gradient descent, the memory allocation is generally much larger - as expected - so we graph against every millionth allocated memory block.
We also observe generally constant space overhead during private gradient descent. However the space overhead is much larger here since we leverage extra space for vectorization and concurrency to improve time efficiency.
Limitations of Random Number Generation#
In conclusion, while some bottlenecks may exist, there are techniques we can use to keep both the space and time cost of differential privacy generally low (constant) throughout the lifetime of program evaluation.
Why do any bottlenecks exist, and why are they particular to differential privacy? In order to preserve the guarantee of differential privacy, we require high-quality entropy. This is a limited resource because it generally relies on some external source of non-deterministic environmental input. Examples of non-determinintic entropy sources can include disk/network IO, keyboard presses, and mouse movement.
Usually this entropy is stored in some special buffer or file to be retrieved and used later on.
with open("/dev/random", 'rb') as file:
print(file.read(8))
b'wsyJ\xe4NJ\x9c'
Alternatively, we could use:
import os
os.urandom(32)
b'\x8a\xea3\xdd\xae\x9e\xf9I\xf3|A\xb0\xab\x84\x89P\x8a\xcd\xf2H:(\x821\xfc\x0c\x16<4\xb4\xa2\x04'
Or:
import secrets
secrets.token_bytes(32)
b'\xb7\x96H\xaf\xe3?\xea\x91N\x0c\xc9\xf5\xc3\xed_\xd0\x87\x10M\xa7\r\x8684`\xb1\xa4\x0er\xbb\x01?'
In general, in different programming languages and operating systems, there are several options for random number and seed generation, with varying applicability for use cases such as: modeling, simulation, or production of cryptographically strong random bytes suitable for managing sensitive user data at scale.